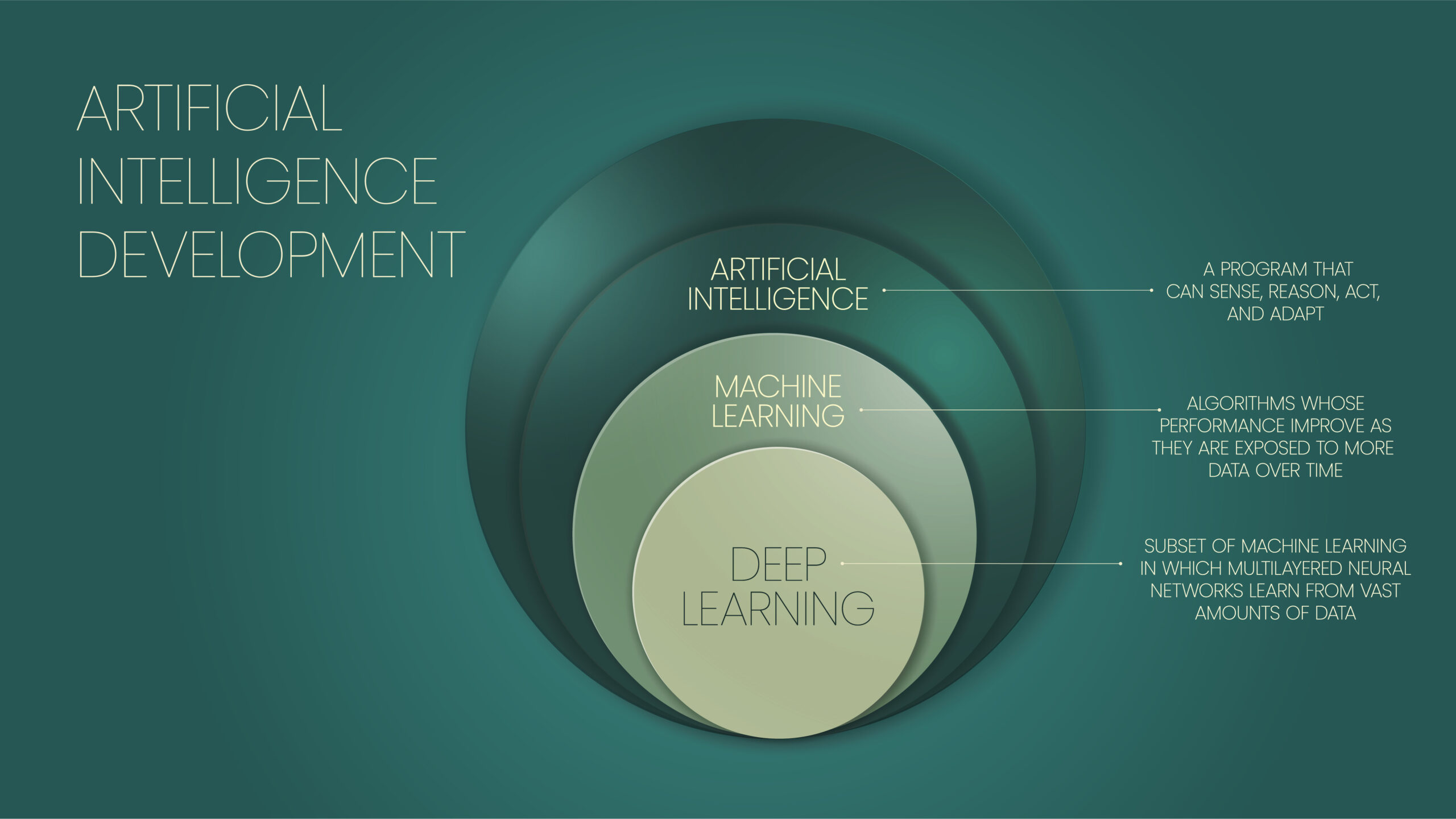
機械学習とは?
機械学習(Machine Learning)は、コンピュータがデータを分析し、そのデータから学習することで、特定のタスクを自動的に遂行できるようにする技術です。
従来のプログラミングとは異なり、明確な手順を事前に定義するのではなく、モデルを訓練し、そのモデルが自ら規則を見つけ出す仕組みです。
例えば、電子メールのスパムフィルタリングや画像認識など、多くの分野で応用されています。
なぜ機械学習が注目されているのか
機械学習は、ビッグデータの普及や計算能力の向上とともに、非常に注目されています。
膨大なデータから規則やパターンを見つけ出し、自動化された意思決定や予測を行うことが可能になり、これによりビジネスや産業界での効率化が進んでいます。
また、AI(人工知能)の一分野としても位置づけられており、今後もさらなる成長が期待されています。
Pythonで機械学習を始めるための準備
Pythonは、機械学習を学び始めるのに最適なプログラミング言語です。
その理由は、豊富なライブラリとツールが整っており、初心者から専門家まで幅広く活用できるからです。
ここでは、Pythonを使って機械学習を始めるために必要な準備について説明します。
開発環境のセットアップ
まず、Pythonの開発環境を整える必要があります。
最も簡単な方法は、AnacondaというPythonディストリビューションをインストールすることです。
Anacondaには、機械学習に必要なライブラリやツールがあらかじめインストールされているため、スムーズに開発を始めることができます。
- Anaconda公式サイトからインストーラをダウンロードしてインストールします。
- インストール後、ターミナルやコマンドプロンプトで次のコマンドを実行し、仮想環境を作成します。
conda create -n ml-env python=3.8
conda activate ml-env代表的なライブラリのインストール
Pythonには、機械学習をサポートする強力なライブラリが数多く存在します。
以下は、機械学習に頻繁に使用される代表的なライブラリです。
- scikit-learn: 機械学習アルゴリズムの実装や評価をサポートするライブラリ。
- Pandas: データの操作と解析に便利なライブラリ。特にデータフレーム形式での処理が強力です。
- NumPy: 数値計算や配列操作のための基本ライブラリ。
次のコマンドで、これらのライブラリをインストールします。
pip install scikit-learn pandas numpyこれで、Python環境のセットアップが完了しました。
次のステップでは、具体的な機械学習アルゴリズムの実装に移ります。
機械学習の基本アルゴリズム
機械学習にはさまざまなアルゴリズムがありますが、ここでは初心者向けに理解しやすい3つの基本アルゴリズムを紹介します。
それぞれのアルゴリズムの目的と特徴について説明し、Pythonでの実装例も示します。
線形回帰(Linear Regression)
線形回帰は、連続的な数値データの予測を行うアルゴリズムです。
例えば、過去のデータをもとに売上や気温などの未来の値を予測する場合に使われます。
このアルゴリズムは、データ間の直線的な関係をモデル化します。
Pythonでの線形回帰実装例
from sklearn.linear_model import LinearRegression
import numpy as np
# ダミーデータ
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 2, 3, 4, 5])
# モデルの作成と訓練
model = LinearRegression()
model.fit(X, y)
# 予測
prediction = model.predict([[6]])
print(f"6に対する予測: {prediction}")
決定木(Decision Tree)
決定木は、分類と回帰の両方に使用できるアルゴリズムです。
データをツリー構造に基づいて分割し、最適な結果を予測します。
特徴の値に基づいて、「もし~ならば」というルールを用いて分類を行います。
Pythonでの決定木実装例
from sklearn.tree import DecisionTreeClassifier
# ダミーデータ
X = [[0, 0], [1, 1]]
y = [0, 1]
# モデルの作成と訓練
clf = DecisionTreeClassifier()
clf.fit(X, y)
# 予測
prediction = clf.predict([[2, 2]])
print(f"2, 2に対する予測: {prediction}")
k近傍法(k-Nearest Neighbors, kNN)
k近傍法(kNN)は、データの分類に使用されるシンプルなアルゴリズムです。
新しいデータポイントを、既存のデータポイントの中から「最も近いk個のポイント」のラベルに基づいて分類します。
kが大きいほど、より多くの近傍データを参照して判断を行います。
PythonでのkNN実装例
from sklearn.neighbors import KNeighborsClassifier
# ダミーデータ
X = [[0, 0], [1, 1], [2, 2]]
y = [0, 1, 1]
# モデルの作成と訓練
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(X, y)
# 予測
prediction = neigh.predict([[1.5, 1.5]])
print(f"1.5, 1.5に対する予測: {prediction}")
機械学習モデルの評価と改善
機械学習モデルが正しく動作しているかを判断するためには、モデルの精度やパフォーマンスを評価することが重要です。
また、モデルのパフォーマンスを向上させるために、ハイパーパラメータのチューニングを行うことも一般的です。
ここでは、モデルの評価指標と改善方法について説明します。
モデルの評価指標
機械学習モデルの評価には、さまざまな指標があります。代表的な評価指標をいくつか紹介します。
- 正解率(Accuracy): 正しく分類されたデータの割合。分類問題で最も一般的な評価指標です。
- 精度(Precision): 予測が正であるとき、実際に正であるデータの割合。
- 再現率(Recall): 実際に正であるデータのうち、予測が正であるものの割合。
- F値(F1-score): 精度と再現率の調和平均で、バランスの取れた評価を行いたい場合に使用されます。
Pythonでの評価指標計算
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 例として、実際のラベルと予測ラベル
y_true = [0, 1, 1, 0]
y_pred = [0, 1, 0, 0]
# 各評価指標の計算
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"Accuracy: {accuracy}, Precision: {precision}, Recall: {recall}, F1-score: {f1}")
ハイパーパラメータのチューニング
機械学習モデルの性能を向上させるためには、モデルのハイパーパラメータを調整することが重要です。
ハイパーパラメータは、モデルが学習を始める前に設定するパラメータで、例えば決定木の深さやk近傍法のk値などが該当します。
これらのパラメータを適切に設定することで、モデルの精度を向上させることが可能です。
グリッドサーチを使ったハイパーパラメータのチューニング
グリッドサーチは、ハイパーパラメータの組み合わせを試行し、最適な設定を見つけるための手法です。
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.datasets import load_iris
# データの読み込み(Irisデータセットを使用)
iris = load_iris()
X = iris.data # 特徴量データ
y = iris.target # ラベルデータ
# ハイパーパラメータの候補を定義
param_grid = {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf']}
model = SVC()
# グリッドサーチの実行
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X, y)
# 最適なハイパーパラメータを表示
print(f"Best parameters: {grid_search.best_params_}")
まとめ
Pythonを使った機械学習の入門ガイドを通じて、機械学習の基本的な概念やアルゴリズム、モデルの評価と改善方法について学んできました。
機械学習は、データを使って予測や分類を行うための強力なツールであり、今後さらに発展が期待される分野です。
Pythonは、機械学習のための豊富なライブラリやツールが揃っており、初心者でも手軽に始められる環境が整っています。
これまで紹介した線形回帰、決定木、k近傍法などのアルゴリズムは、機械学習の基礎を学ぶうえで非常に重要です。

